
Apple Intelligence Faces Nvidia, Google, and China Roadblocks
Apple’s latest AI models rely on both in-house chips and Nvidia GPUs, but regulatory hurdles complicate a China launch.

This article originally appeared on Weijin Research on Sina on June 9, 2026. Original Chinese title: 「完整版Apple Intelligence,苹果向英伟达低头,落地中国又有新问题」. It has been translated and adapted for an English-speaking audience.
Markets were waiting for Apple to unveil something new at WWDC, but the stock price turned from gains to losses. It seemed investors were not satisfied with the report card Cook delivered in his swan song.
Still, the good news is that nobody has really cracked the consumer AI path yet. John Ternus, who will take over as CEO in September, still has a shot.
At the very least, at this WWDC, Apple finally tried to explain what Apple Intelligence actually is and what the Apple Foundation Model (AFM) behind it looks like.
In Apple’s own telling, the on-device model still carries a distinctly “Apple flavor,” and the cloud model isn’t just a hollow Gemini shell. Even more surprisingly, Apple has bowed to Nvidia for the first time: with Private Cloud Compute (PCC) safeguards in place, its most powerful new model can also run on non-Apple Silicon.
Deep collaboration, but zero Google content.
Since its first unveiling two years ago, Apple Intelligence has remained a fuzzy concept. The market has struggled to piece together its full architecture from Apple’s scattered descriptions. This time, Apple finally used a single diagram to show the entire tech stack of Apple Intelligence. It looks like a five-layer cake, covering users, devices, models, systems, and apps from the inside out.
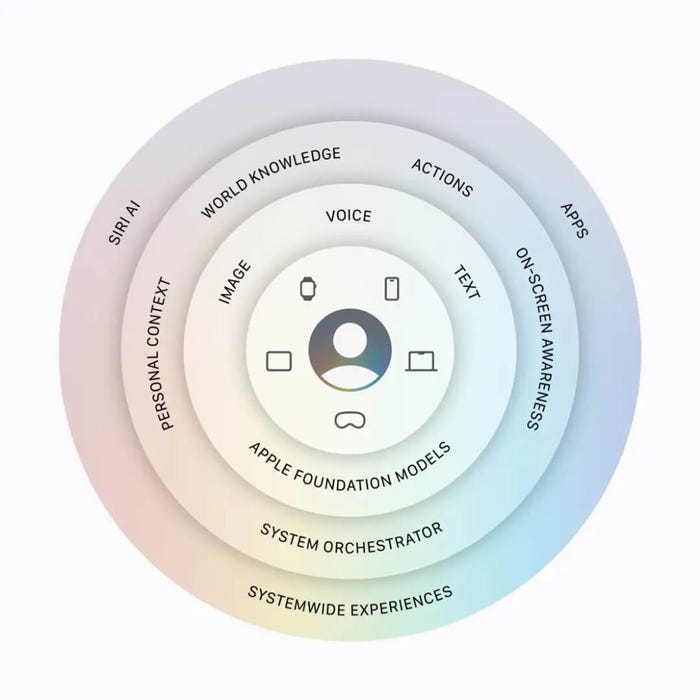
The core of Apple Intelligence is, of course, the Apple Foundation Models (AFM). The family has quietly advanced to a third generation, maintaining a yearly cadence. This time, Apple released five models at once: the on-device AFM 3 Core and AFM 3 Core Advanced, and the cloud-based AFM 3 Cloud, AFM 3 Cloud Image, and AFM 3 Cloud Pro.
The on-device models handle most of the processing that happens locally on Apple devices. When local compute is insufficient, a System Orchestrator routes requests to three cloud models deployed in Apple’s Private Cloud Compute platform. Apple positions AFM 3 Cloud Pro as “comparable in performance to Google’s Gemini frontier models.”
In a conversation with media after the presentation, Apple’s AI chief Craig Federighi emphasized that Apple Intelligence has a “Google Assistant component footprint of zero”: it did not directly adopt the models Google offers to Gemini users, there is no Gemini client code integrated into iOS, the system’s knowledge base is not Google Search, and it does not use any of Google’s ready-made infrastructure or methods.
Apple acknowledges that the models were pre-trained on the latest generation of cloud TPU accelerators, but during inference, they were designed specifically for Apple’s own deployment architecture. The first four models are primarily optimized for Apple Silicon; only AFM 3 Cloud Pro is optimized for Nvidia GPUs.
According to Apple, AFM models are trained on its own proprietary data, and Gemini’s role is mainly that its outputs are used for further “refinement.” This appears to suggest a form of legitimate “distillation.”
On-Device Models: Distinctly Apple
Apple disclosed the parameter sizes of its on-device models. The third-generation AFM Core is a dense model with about 3 billion parameters. AFM Core Advanced is a special sparse model with a total parameter count of about 20 billion.
Through a special design, however, AFM Core Advanced only needs to dynamically activate 1 to 4 billion parameters during actual inference, delivering what Apple calls “Inference-Time Elasticity.”
Previously, both traditional dense models and sparse activation models like MoE required all model weights to reside in DRAM. That meant that as model size grew, memory usage increased, making them harder to run on consumer hardware.
To break through this limitation, AFM 3 Core Advanced introduces a new sparse activation architecture built on a technique Apple researchers call Instruction-Following Pruning (IFP). Unlike traditional approaches that require loading the entire model into DRAM, AFM 3 Core Advanced stores the full model in NAND flash.
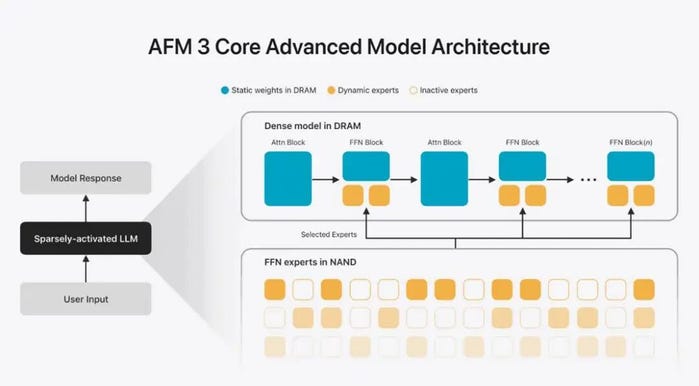
Because the bandwidth between NAND and DRAM is far lower than in-memory access speed, it cannot support the kind of frequent switching and loading of expert weights that occurs during each token generation step in a conventional MoE model. AFM 3 Core Advanced therefore shifts most routing decisions to the prompt phase.
This echoes the LLM in a Flash research Apple explored back in 2023, which used flash storage to overcome memory constraints for running large language models on phones. By 2025, Apple published work on instruction-following pruning, where the model dynamically selects parameters most relevant to the task based on the user’s prompt input.
Specifically, a lightweight dense module first chooses a set of experts after the user enters a prompt, then periodically re-evaluates and adjusts that expert mix during generation. To further reduce data transfer overhead, the model uses a high proportion of “shared experts” that stay active at all times, while “routed experts” (selected dynamically based on the input) are loaded into DRAM only when needed.
For tasks of different complexity, AFM 3 Core Advanced can also load more parameters incrementally, scaling its reasoning capacity on demand. The idea is to treat NAND as a “parameter warehouse” and DRAM as a “dynamic workspace,” pushing past mobile memory limits by minimizing how many parameters must sit resident in memory at any time.
Even so, this capability is currently available only on the iPhone 17 Pro, M3 Macs, and M4 iPads. That means 12GB of unified memory has become the effective baseline requirement for running AFM 3 Core Advanced. For Apple, devices capable of running larger on-device models are emerging as the foundational hardware platform for the next generation of AI experiences.
The cloud model bows to Nvidia
At the same time, with the launch of AFM 3 Cloud Pro (its most powerful cloud model), Apple has, for the first time in a meaningful sense, bowed to Nvidia.
Over the past few years, Apple has tried to build a unified AI architecture from on-device to cloud using Apple Silicon alone. But as base model size keeps ballooning, the demands of cloud training and inference for GPU clusters, high-bandwidth interconnects, and mature software ecosystems have kept rising. Apple has been forced to acknowledge that its own silicon is still not enough for the most cutting-edge large model work.
This is also the first time Apple’s Private Cloud Compute (PCC) framework has had to extend into third-party data centers.
Apple’s VP of Software, Sebastien Marineau-Mes, said the company wanted to use Nvidia’s latest-generation GPUs, but only under the condition that they met PCC’s five core principles: stateless computation, enforceable guarantees, no privileged runtime access, non-targetability, and verifiable transparency. Recent improvements Nvidia has made in confidential computing allowed Apple to build a system that satisfies its PCC standards.
What’s more telling is that Apple did not simply buy Nvidia GPUs to build its own PCC clusters. Instead, it brought in Google as an intermediary. Google Cloud is responsible for deploying Nvidia GPUs that support confidential computing. The full architecture pairs them with Intel CPUs supporting Trust Domain Extensions (TDX) and Google’s Titan security chip as the hardware root of trust.
The China market, absent for now
Apple Intelligence and the Siri AI it powers are not currently available in the Chinese or EU markets.
Regulatory compliance is the real choke point. Earlier, Apple integrated Siri with ChatGPT and planned to use an Extensions tool so Siri could invoke any AI app available for download on the App Store, including Gemini, Claude, and others. But none of those models had completed the required algorithm registration and security assessments for generative AI services in China. Lacking its own foundation model capabilities, Apple had at one point been looking for cooperation from a Chinese partner.
Now, in some respects, the narrative that AFM models have “zero Google content” makes regulatory compliance easier. AFM has become a model system fully under Apple’s control. Apple holds far greater autonomy over model weights, content safety mechanisms, and liability. For regulators, the entity to be reviewed and held accountable is primarily Apple itself, not a set of overseas model providers, so the compliance review becomes significantly simpler. There may be no need, perhaps, to tie the product to a Chinese model partner.
This is especially true for on-device models, where data stays entirely local and involves no cross-border data flows. And for cloud models running on Apple Silicon clusters, Apple could in theory replicate the “Guizhou on the cloud” model, keeping all data, models, and compute resources within the country.
The real difficulty lies with AFM 3 Cloud Pro. It effectively represents the full Apple Intelligence experience. So far, Apple hasn’t demonstrated that its homegrown chip ecosystem can independently support model inference at that tier. Even if the model itself clears compliance, AFM 3 Cloud Pro still faces a thornier infrastructure problem. The advanced Nvidia AI compute power Apple depends on will not necessarily be available in China at the same specifications.
If AFM 3 Cloud Pro’s best performance requires Nvidia’s latest-generation GPUs, the US may be unwilling to let that compute capacity enter the Chinese market. And if Apple is limited to export versions of chips with restricted performance, the proposition in China becomes somewhat hollow.
Perhaps this time, Apple will have to start fresh and look for a Chinese AI chip partner. To prevent the capability gap between the China and global versions from widening further, it will have to invest serious effort in coordination and adaptation.